分布式文件存儲SeaweedFS的數據存儲設計與實現 數據處理與存儲支持服務解析
在當今大數據時代,數據處理與存儲支持服務已成為各類應用的核心基礎。分布式文件存儲系統SeaweedFS憑借其簡潔高效的設計,為解決海量非結構化數據存儲問題提供了強有力的支持。本文將深入探討SeaweedFS在數據存儲層面的設計與實現,揭示其如何為上層的數據處理提供堅實可靠的存儲服務。
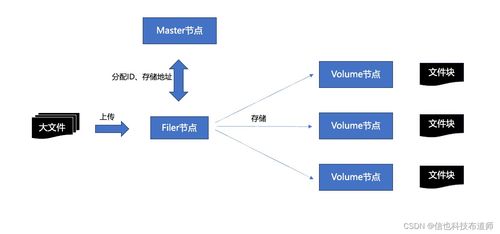
SeaweedFS的設計哲學是“簡單而強大”,其核心架構由兩部分組成:管理文件元數據的Master Server和實際存儲文件數據的Volume Server。這種清晰的分層設計使得系統具有出色的可擴展性和高可用性。在數據存儲層面,SeaweedFS采用了一種巧妙的設計:將文件存儲抽象為一個個固定大小的“卷”(Volume),每個卷由多個數據塊組成,支持高效的讀寫操作。
在數據存儲的實現上,SeaweedFS采用了幾項關鍵技術:
第一,智能數據分片與復制機制。SeaweedFS會自動將大文件分割成固定大小的數據塊(默認為32MB),并將這些數據塊分布到不同的Volume Server上存儲。系統支持可配置的復制因子,確保數據的高可用性和容錯能力。這種設計不僅提高了數據讀寫的并發性能,還通過數據冗余保障了數據安全性。
第二,高效的數據索引管理。Master Server采用輕量級設計,僅存儲卷到Volume Server的映射關系,而不存儲具體的文件元數據。文件ID直接編碼了卷ID和文件在卷內的偏移量,這種設計大大減少了元數據管理的開銷,使得Master Server可以輕松管理數十億級別的文件。
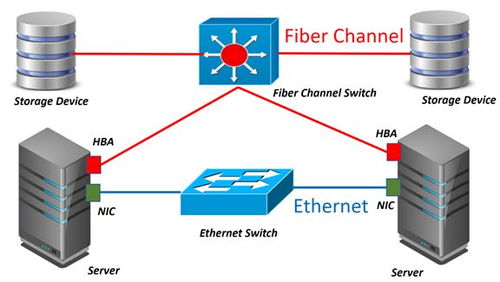
第三,優化的數據訪問路徑。客戶端在讀寫文件時,首先從Master Server獲取卷的位置信息,然后直接與對應的Volume Server通信。這種去中心化的數據訪問模式避免了單點瓶頸,顯著提高了系統的吞吐能力。
第四,靈活的數據存儲策略。SeaweedFS支持多種存儲后端,包括本地文件系統、云存儲服務等。Volume Server可以采用不同的存儲介質和配置,滿足不同場景下的性能與成本需求。
在數據處理支持方面,SeaweedFS提供了豐富的API接口,包括RESTful API和FUSE文件系統接口,使得各種數據處理框架(如Hadoop、Spark)可以輕松集成。系統還支持數據壓縮、加密等特性,為敏感數據的處理提供安全保障。
SeaweedFS的數據存儲設計充分考慮了實際運維需求。系統提供了詳細的數據統計和監控接口,支持數據的均衡分布和熱點數據的自動遷移。當存儲節點出現故障時,系統能夠自動檢測并啟動數據恢復流程,確保存儲服務的連續性。
SeaweedFS通過簡潔而高效的數據存儲設計,為大規模數據處理應用提供了可靠的基礎設施支持。其模塊化的架構、智能的數據分布策略和豐富的API接口,使得它能夠適應從傳統企業應用到現代云原生環境的多樣化需求。隨著數據量的持續增長和處理需求的不斷演進,SeaweedFS這類輕量級、高可擴展的分布式存儲系統將在數據處理生態中扮演越來越重要的角色。
如若轉載,請注明出處:http://www.xaxcyy.com/product/45.html
更新時間:2026-02-19 22:57:27